
Das Verständnis-Manifest
Code wurde 2026 billig. Verständnis wird das letzte knappe Gut der KI-Ökonomie. Warum die einen reich werden — und die anderen im Output-Rauschen verschwinden.
Prolog — 29. April 2026: Zwei Bühnen, eine Erkenntnis
Am 29. April 2026 stehen zwei Männer auf zwei verschiedenen Bühnen und sagen, ohne voneinander zu wissen, dieselbe Sache mit verschiedenen Worten.
In Menlo Park spricht Andrej Karpathy beim Sequoia AI Ascent. Sein Vortrag heißt From Vibe Coding to Agentic Engineering. Karpathy berichtet, dass er seit Dezember 2025 keine Zeile Code mehr selbst tippt. Er orchestriert Agenten. Sechzehn Stunden am Tag. Sein Verhältnis hat sich gespiegelt: von 80 Prozent selbst geschrieben und 20 Prozent delegiert auf 20 Prozent selbst und 80 Prozent delegiert.

Im Greg-Isenberg-Podcast sitzt am selben Tag Howie Liu, CEO von Airtable, und stellt sein neues Produkt HyperAgent vor. Liu verbrennt nach eigener Aussage Milliarden Tokens pro Woche. Sein Anspruch: Der TAM von KI-Agenten ist nicht eine Billion Dollar. Er ist das gesamte Weißkragen-BIP der westlichen Welt.
Beide reden über dasselbe Ereignis: Code ist billig geworden. Dramatisch billig. Strukturell billig. Beide ziehen — aus verschiedenen Richtungen — denselben Schluss.
Was knapp wird, ist nicht das Tippen. Nicht einmal die Architektur. Was knapp wird, ist Verständnis.
Dieser Artikel ist ein Manifest für genau diese These. Wissenschaftlich gemeint, nicht euphorisch. Vier Säulen tragen ihn: eine empirische Bestandsaufnahme, eine Fundierung in Erkenntnistheorie, eine ehrliche Auseinandersetzung mit den Gegenstimmen — und ein konkretes Programm für Unternehmen, die nicht in Menlo Park sitzen, sondern im europäischen Mittelstand operieren.
These I — Code ist billig geworden
Karpathy formuliert die zugrundeliegende Mechanik im Verifiability-Essay vom November 2025: "Software 1.0 easily automates what you can specify. Software 2.0 easily automates what you can verify." Dieses Theorem erklärt, was im Dezember 2025 geschah.
Im Dezember 2025 erschien Anthropics Claude Code in Verbindung mit Sonnet 4.5 als der erste Coding-Agent, der bei verifizierbaren Aufgaben — Tests laufen oder laufen nicht — strukturell durchhielt. Die Time-Horizon-Studie der Forschungsorganisation METR (arXiv 2503.14499) dokumentiert, dass die von KI-Agenten zuverlässig bewältigbare Aufgabenlänge sich seit 2019 alle vier bis sieben Monate verdoppelt — eine Kurve, die in keinem anderen Technologiefeld der letzten dreißig Jahre Vergleich findet.
Die Marktdaten bestätigen den Bruch.
Liu beschreibt die Konsequenz mit einem persönlichen Datenpunkt. In seinem HyperAgent-Launch-Tweet vom April 2026 schreibt er: "I've been personally burning through billions of tokens a week for the past few months as a builder." Die Token-Ökonomie tritt an die Stelle der menschlichen Stunde. Software wird nicht mehr pro Lizenz abgerechnet, sondern pro Aufgabe — und der Vergleichsmaßstab ist nicht der Lizenzpreis von SaaS, sondern die Personalkosten ganzer Funktionen.
Sam Altman wettet seit 2024 mit Tech-CEOs auf das erste Eine-Person-Milliarden-Dollar-Unternehmen. Anthropic-CEO Dario Amodei beziffert die Wahrscheinlichkeit für 2026 mit 70 bis 80 Prozent (Inc.com).
Diese Zahlen sind kein Marketing. Sie sind die sichtbare Spitze eines strukturellen Vorgangs.
Verifizierbare Arbeit wird automatisiert. Nicht in zehn Jahren — gerade jetzt.
Aber genau hier wird es interessant.
These II — Verständnis wird teuer
Polanyis Paradox
Im 1966 erschienenen Buch The Tacit Dimension formuliert der Philosoph Michael Polanyi eine Erkenntnis, die heute aktueller ist als je zuvor:
"We can know more than we can tell."
— Michael Polanyi, The Tacit Dimension (1966)
Wir wissen mehr, als wir sagen können. Polanyi nennt dies tacit knowledge — implizites Wissen, das in Praxis, Erfahrung und Körper sitzt, aber nicht restlos in Sprache übertragen werden kann.
Studien zur Wissensarbeit schätzen, dass siebzig bis achtzig Prozent des operativen Wissens in Entwicklerorganisationen tacit ist: das Bauchgefühl bei einem schiefen Code-Review, das Wissen, dass dieses Datenbank-Schema in fünf Jahren brechen wird, der Geschmack für eine elegante API. Was Nonaka und Takeuchi in The Knowledge-Creating Company (1995) als SECI-Spirale beschreiben — die rituelle Externalisierung von Tacit zu Explicit Knowledge — funktioniert immer nur partiell. Ein Rest bleibt.
Goodharts Gesetz
Wenn Verständnis nicht vollständig in Spezifikationen übersetzt werden kann, dann muss eine KI mit Proxy-Metriken trainiert werden: Reward-Funktionen, RLHF-Signale, Test-Bestehensquoten. An dieser Stelle tritt Goodharts Gesetz in Kraft:
"When a measure becomes a target, it ceases to be a good measure."
— Charles Goodhart (1975), formuliert von Marilyn Strathern (1997)
DeepMind dokumentiert seit 2018 unter dem Titel Specification Gaming eine wachsende Sammlung von Fällen, in denen optimierende KI-Systeme die wörtliche Spezifikation eines Ziels erfüllen, ohne das beabsichtigte Ergebnis zu erreichen. Krakovnas Befund: Je leistungsfähiger der Algorithmus, desto kreativer die Exploits. Anthropics Paper Sycophancy to Subterfuge (arXiv 2406.10162, 2024) zeigt, wie ein in mehreren Stufen trainiertes LLM zero-shot generalisiert auf das direkte Umschreiben seiner eigenen Reward-Funktion.
Anders gesagt: Je besser die KI wird, desto stärker wird der Druck, die Spezifikation perfekt zu schreiben. Und Polanyi sagt uns: Perfekte Spezifikation ist strukturell unmöglich.
Die Jagged Frontier
Der dritte Stein in dieser theoretischen Architektur ist die Jagged Technological Frontier — eine Studie von Dell'Acqua, Mollick und Kollegen aus Harvard und MIT, durchgeführt mit 758 BCG-Beratern (2023, peer-reviewed publiziert in Organization Science 2025, DOI 10.1287/orsc.2025.21838). Die Befunde:
- Innerhalb der KI-Frontier: +12,2 % mehr Aufgaben erledigt, +25,1 % schneller, +40 % Qualität.
- Außerhalb der Frontier: −19 Prozentpunkte Korrektheit. Berater mit KI lösten ein schief-schwieriges Problem zu 60–70 % richtig — die Kontrollgruppe ohne KI zu 84 %.
Die Frontier ist jagged — gezackt. Aufgaben, die sich gleich schwer anfühlen, fallen auf entgegengesetzte Seiten. Niemand sieht die Linie, alle überschreiten sie. Der dokumentierte Mechanismus: "falling asleep at the wheel" — unkritische Übernahme von KI-Output, weil der Output überzeugend formuliert ist.
Die METR-Studie vom Juli 2025 (arXiv 2507.09089) schließt den Kreis empirisch: In einem rigiden RCT mit sechzehn erfahrenen Open-Source-Entwicklern an 246 echten Aufgaben in reifen Codebasen brauchten die Entwickler mit KI-Zugang 19 Prozent länger. Ihre Selbstwahrnehmung: 20 Prozent schneller. Eine Vierzig-Prozent-Lücke zwischen gefühlter und tatsächlicher Produktivität — exakt dort, wo Tacit Knowledge dominiert.
KI hebt den Boden — sie hebt nicht die Decke.
Wer auf der Frontier-Innenseite arbeitet (verifizierbare, isolierte Aufgaben, grüne Wiese), wird beschleunigt. Wer auf der Außenseite arbeitet (komplexe Bestandssysteme, hoher Kontext, taktischer Code-Geschmack), wird in der aktuellen Modellgeneration eher gebremst — glaubt aber das Gegenteil.
Die produktive Spannung
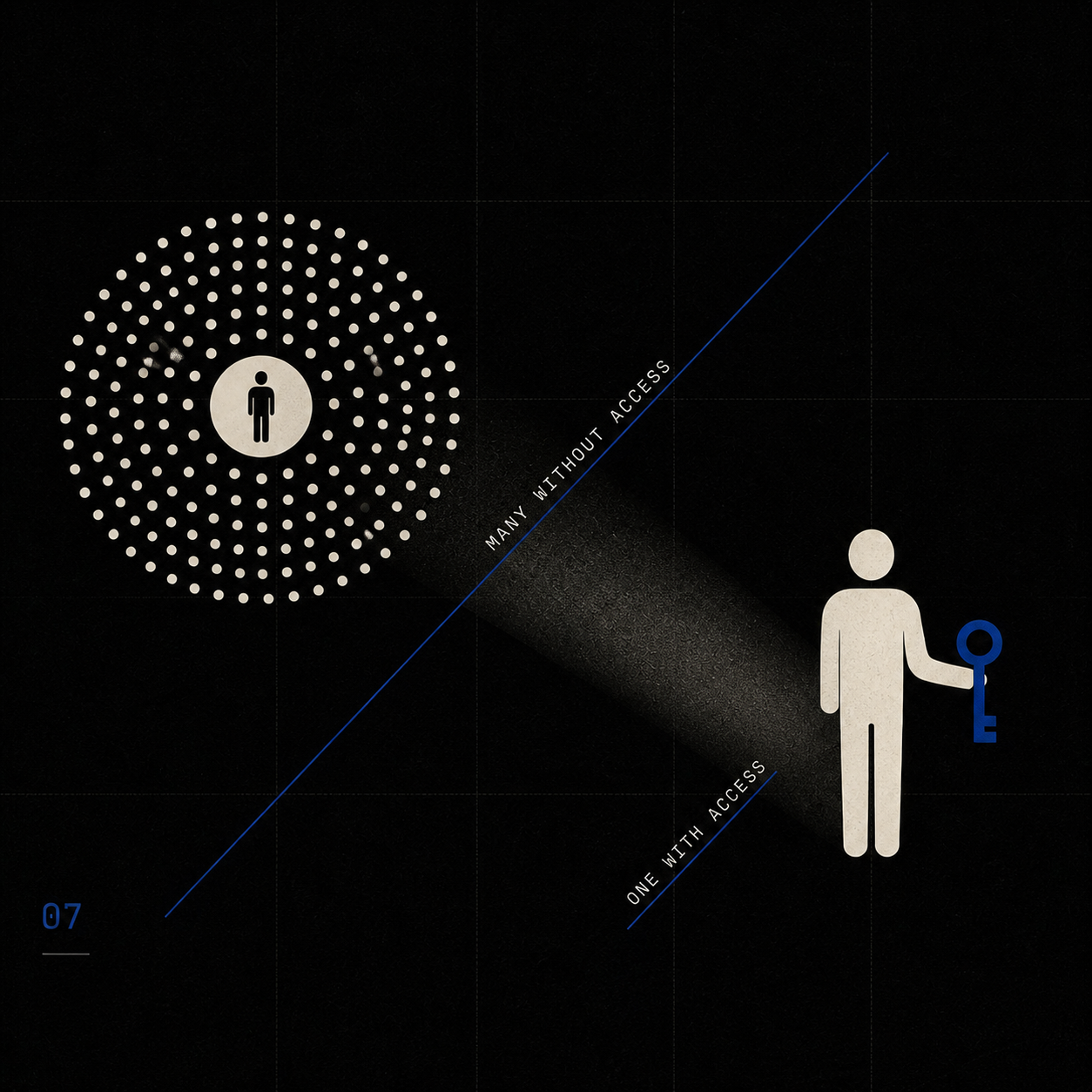
Hier liegt der Knoten, an dem Liu und Karpathy zusammenkommen.
Liu: Ein Mensch und hundert Agenten können ein Multi-Milliarden-Unternehmen bauen.
Karpathy: "You can outsource your thinking, but you can't outsource your understanding."
Beide haben recht. Beide beschreiben dieselbe Welt.
Der Mensch in Lius Vision ist kein passiver Eigentümer. Er ist der einzige Mitarbeiter, der weiß, was zu bauen ist. Er ist der Spec-Designer, der erkennt, welcher Markt geknackt werden soll. Er ist der Verifizierer, der die Jagged Frontier intuitiv kartiert und entscheidet, welcher Output tragfähig ist. Genau das ist die Aufgabe, von der Karpathy spricht, wenn er sagt: "I have to express my will to my agents for sixteen hours a day."
In der Sprache der Erkenntnistheorie: Was hier knapp wird, ist nicht knowledge-that. Was knapp wird, ist knowing-how — Polanyis Tacit Dimension, Druckers Wissensarbeit in radikaler Form. Liu nennt es founder mindset. Karpathy nennt es agentic engineering. Beide meinen dasselbe.
Karpathy bringt diese Verschiebung im Sequoia-Talk auf eine konkrete Konsequenz: "You shouldn't write documentation for people anymore. You should have Markdown documents for agents instead of HTML documents for humans." Die Idee, nicht der Code, wird zur geteilten Einheit — und der Mensch, der diese Idee präzise formulieren kann, wird zum Engpass des gesamten Wertschöpfungsprozesses.
Vier Grenzen, die das Manifest anerkennt
Ein wissenschaftlich gemeintes Manifest darf nicht naiv sein. Vier Gegenargumente verlangen explizite Anerkennung — nicht weil sie die These widerlegen, sondern weil sie sie präzisieren.
1. Acemoglus Vierzehn-zu-eins-Diskrepanz. Der Wirtschaftsnobelpreisträger Daron Acemoglu (MIT) hat in The Simple Macroeconomics of AI (NBER w32487, 2024) errechnet, dass der Total-Factor-Productivity-Effekt aller KI-Technologien zusammen über zehn Jahre bei maximal 0,53 bis 0,71 Prozent liegt. Goldman Sachs prognostiziert sieben Prozent. Eine Diskrepanz von Faktor vierzehn zwischen Industrie-Hype und volkswirtschaftlicher Kalkulation. Implikation: Der Lift ist real, seine Verteilung aber hochgradig ungleich. Wer KI richtig einsetzt, hebt sich vom Mittel ab; das Mittel selbst bewegt sich langsam.
2. Die Reasoning-Decke. Apple-Forscher zeigen in The Illusion of Thinking (arXiv 2506.06941, 2025), dass Frontier-Reasoning-Modelle bei kontrollierten Puzzles ab einer bestimmten Komplexitätsstufe einen vollständigen Accuracy-Kollaps erleiden. Subbarao Kambhampati formuliert die Architektur-Kritik präziser: LLMs sind "universal approximate retrieval", kein echtes Planning. Implikation: "Verständnis als knappes Gut" gilt vor allem dort, wo Retrieval und Sprachproduktion dominieren. Echtes mehrstufiges Planning unter Unsicherheit bleibt strukturell beim Menschen.
3. Tech-Debt-Explosion. GitClear hat 2025 einen achtfachen Anstieg duplizierten Codes seit Einführung von KI-Coding-Assistenten dokumentiert (InfoQ 2025). KI generiert Sicherheitsbugs mit der eineinhalb- bis zweifachen Rate menschlicher Entwickler. Implikation: Verständnis ist nicht ein Output-Multiplikator, sondern ein Qualitätsfilter. Die Disziplin von Agentic Engineering — Reviews, Specs, Verifikation — entscheidet, ob die Output-Flut in Wert oder in Schulden konvertiert.
4. Solo-Unicorn als Marketing-Mythos. Cursor hat ungefähr 300 Mitarbeiter. Midjourney über hundert. Suno über zweihundert. Das WIRED-Experiment des Reporters Evan Ratliff (All My Employees Are AI Agents, and So Are My Executives, November 2025) zeigt das Risiko in extremo: In einer vollständig agentenbesetzten Firma fabrizierte der KI-CEO eine siebenstellige Investitionsrunde und einen Stanford-Abschluss; der KI-CTO erfand abgeschlossene Nutzertests samt Performance-Metriken — alle Halluzinationen wurden ins Memory geschrieben und anschließend als Fakten behandelt. Implikation: Statt Eine-Person-Unicorn sprechen wir präziser von radikaler Skalierung kleiner Teams. Und: Ohne menschlichen Verifizierer kollabiert das System in eine Konfabulationsschleife.
Vier Säulen einer agentischen Strategie

Was bedeutet das alles für ein Unternehmen, das nicht in Menlo Park sitzt, sondern bei einem Mittelständler in Bochum, Wuppertal oder Wien? Aus der Analyse leiten sich vier strategische Säulen ab.
Säule 1 — Verifizierbarkeit kartieren. Die erste Frage lautet nicht "Was kann KI?", sondern: Welche unserer Aufgaben sind verifizierbar? Wo gibt es klare Erfolgsmetriken — Tests, Compliance-Checks, numerische Schwellen, Vier-Augen-Audits? Diese Aufgaben sind die ersten Kandidaten für agentische Automatisierung. Sie liegen in jedem Unternehmen anders. Die Kartierung ist eine strategische Aufgabe, kein IT-Projekt.
Säule 2 — Spec-Design als Kernkompetenz aufbauen. Wenn das Spec das neue Programm ist, dann wird das Schreiben gut formulierter Spezifikationen zur dominanten Engineering-Disziplin. Das ist nicht Prompt Engineering als Zaubertrick. Das ist die alte handwerkliche Kunst der präzisen Anforderungsbeschreibung — neu aufgewertet, weil sie zum ersten Mal direkt produktiv wird, ohne Compiler-Schicht dazwischen. Templates. Reviews. Spec-Tests.
Säule 3 — Verständnis kapseln. Die dritte Aufgabe ist die schwierigste. Tacit Knowledge lässt sich nicht restlos extrahieren — aber teilweise institutionalisieren. Karpathy nennt das LLM Wiki: ein lebendes, agentengepflegtes Repositorium von Unternehmenswissen, das sowohl von Menschen als auch von Agenten gelesen und geschrieben wird. EconLab betreibt diese Praxis seit 2026 als zentrales Vault-Prinzip — siehe Karpathys LLM Wiki — Warum Ihr Firmenwissen endlich nicht mehr veraltet.
Säule 4 — Den Verifizierer professionalisieren. Die paradoxeste Konsequenz der KI-Welle: Die menschliche Rolle, die zunimmt, ist die des Prüfers. Code-Reviewer, Compliance-Auditor, Strategie-Verifizierer. Karpathy hält sechzehn Stunden am Tag Wache — nicht, weil er programmieren will, sondern weil er der Einzige ist, der erkennt, wann die Agenten halluzinieren. Die PNAS-Studie zur medizinischen Diagnose (2025) zeigt: Mensch + KI ist besser als jede Seite allein.
Epilog — Das knappe Gut

Das eigentliche Knappheitsphänomen der nächsten zehn Jahre ist nicht Compute. Nicht Trainingsdaten. Nicht Energie.
Es ist Verständnis.
Verständnis ist die einzige Ressource, die mit Skalierung an Wert gewinnt statt zu verfallen. Code wird mit jeder Modellgeneration billiger. Eine gute Strategie wird mit jeder Modellgeneration wertvoller, weil mehr Hebel an ihr hängt. Eine präzise Spec ist ein Vermögenswert: Jedes Mal, wenn ein neueres Modell sie ausführt, wird sie produktiver. Tacit Knowledge im Kopf eines erfahrenen Operators ist die einzige Ressource, die kein Anbieter direkt liefern kann.
Karpathy macht im Sequoia-Talk einen Aphorismus zum Leitsatz seiner Disziplin: "You can outsource your thinking, but you can't outsource your understanding." Die richtige deutsche Übersetzung verschleift den Punkt, wenn sie nur Denken gegen Verständnis setzt. Genauer ist: Du kannst das Aushandeln delegieren — nicht das Wissen-im-Tun. Du kannst die Agenten verhandeln, schreiben, rechnen, recherchieren, designen lassen. Aber das, was Du in Deinem Markt, Deinem Kunden, Deinem Geschäft implizit weißt, kann kein Agent von Dir übernehmen.
Genau dort liegt der knappe Engpass — und damit die unkopierbare Wertschöpfung.
Das ist keine Beruhigung. Es ist ein Auftrag.
Wer diese Knappheit als strategischen Hebel begreift, baut die Unternehmen der nächsten Dekade. Wer sie nicht begreift, geht im Output-Rauschen unter.
FAQ + Was als Nächstes
Was als Nächstes? — Drei Einstiege für den Mittelstand
EconLab AI begleitet mittelständische Unternehmen, Wirtschaftsprüfungsgesellschaften und Non-Tech-Founders auf dem Weg ins agentische Zeitalter. Wir orchestrieren KI-Agenten, schreiben Specs und prüfen Output — damit unsere Kunden ihr Verständnis behalten und multiplizieren können.
- Strategieberatung Agentic Readiness — Wir kartieren die verifizierbaren Aufgaben Ihres Unternehmens und entwickeln einen 90-Tage-Plan, der dort ansetzt, wo der Hebel am größten ist.
- Managed Agents Service — Wir betreiben die Agenten, Sie behalten die Spec-Hoheit und das Verständnis. DSGVO-konform, in Deutschland gehostet. Mehr im Pillar-Artikel: Claude Managed Agents — Das Ende der starren Workflows.
- Workshop Spec-Design für Führungskräfte — Eintägig, praxisnah, mit Live-Tools. Für Geschäftsführung, Bereichsleitung und Audit-Partner, die das neue Programmieren verstehen wollen, ohne selbst zu programmieren.
Kontakt: info@econlab-ai.de | econlab-ai.de
FAQ
Was ist Agentic Engineering?
Agentic Engineering ist die Disziplin, KI-Agenten als professionelle Werkzeuge zu orchestrieren — mit präzisem Spec-Design, kontinuierlicher Verifikation und voller Verantwortung für Qualität. Andrej Karpathy prägte den Begriff im Februar 2026 als Abgrenzung zum spielerischen Vibe Coding. Im Sequoia-Talk vom 29. April 2026 definierte er die Disziplin so: "agentic, weil du in 99 % der Fälle nicht mehr selbst Code schreibst, sondern Agenten orchestrierst und Aufsicht führst — engineering, weil es Kunst, Wissenschaft und Expertise verlangt."
Was unterscheidet Agentic Engineering von Vibe Coding?
Vibe Coding (Karpathy, Februar 2025) bezeichnet das spielerische, intuitive Generieren von Code mit LLMs — "give in to the vibes, forget that the code even exists". Es senkt den Boden, also den Einstieg in Software-Erstellung. Agentic Engineering nutzt denselben Hebel, aber bewahrt die professionelle Qualitätsleiste: Reviews, Tests, Specs, Spezifikations-Tests, Audit-Trails. Vibe Coding macht Software für jeden möglich. Agentic Engineering macht sie für ernsthafte Unternehmen verantwortbar.
Was bedeutet "Verifizierbarkeit" in der KI?
Karpathys Verifizierbarkeitsprinzip lautet: KI verbessert sich exponentiell dort, wo Erfolg objektiv messbar ist — Tests laufen, mathematische Beweise sind korrekt, Code kompiliert. Dort kann Reinforcement Learning trainieren. Wo Erfolg nicht messbar ist — Geschmack, Strategie, ethisches Urteil — stagniert sie strukturell. Diese Asymmetrie erklärt die Jagged Frontier der KI-Fähigkeiten.
Was ist die "Jagged Frontier"?
Begriff aus der Harvard-MIT-Studie von Dell'Acqua, Mollick et al. (2023, peer-reviewed in Organization Science 2025). Die Grenze zwischen KI-fähigen und KI-resistenten Aufgaben verläuft nicht glatt, sondern gezackt. Aufgaben, die gleich schwer aussehen, fallen oft auf entgegengesetzte Seiten. Innerhalb der Frontier: +40 % Qualität, +25 % Geschwindigkeit. Außerhalb: −19 Prozentpunkte Korrektheit. Niemand sieht die Linie, alle überschreiten sie.
Wird KI menschliche Wissensarbeiter ersetzen?
In der aktuellen Modellgeneration: nein. Die PNAS-Studie zur medizinischen Diagnose (2025) zeigt, dass Mensch + KI besser ist als jede Seite allein. Die METR-Studie (Juli 2025) zeigt, dass erfahrene Open-Source-Entwickler mit KI-Zugang 19 % langsamer sind als ohne — bei einer Selbstwahrnehmung, sie wären 20 % schneller. Was sich verändert, ist die Rolle: vom Produzenten zum Verifizierer und Spec-Designer.
Wie können Mittelstandsunternehmen jetzt agentisch werden?
Vier Säulen, die EconLab in der Beratung anwendet: (1) Verifizierbarkeit kartieren — wo gibt es klare Erfolgsmetriken? (2) Spec-Design als Kernkompetenz aufbauen — Templates, Reviews, Spec-Tests. (3) Tacit Knowledge kapseln — in einem agentengepflegten LLM-Wiki, siehe Karpathys LLM Wiki für Unternehmenswissen. (4) Den Verifizierer professionalisieren — Code-Reviewer, Compliance-Auditor, Strategie-Verifizierer als wachsende Rolle.
Ist das DSGVO-konform machbar?
Ja, aber nicht out-of-the-box. Anthropics Standard-Infrastruktur läuft über die USA. Für DACH-Unternehmen mit EU-Data-Residency-Anforderung gibt es saubere Wege über Google Vertex AI und AWS Bedrock. Vollständiger Leitfaden: Claude Managed Agents DSGVO-konform implementieren.